- PR_Admin
- Articles
Why an enterprise industrial platform beats siloed tools — and unlocks ai
for operations
Point solutions that pull directly from historians or SCADA solve one problem at a time but multiply security risk, create data drift, overload control networks, and strand your AI ambitions. An enterprise industrial data platform gives you governed, real-time, reusable operations data with the context AI needs—so every new use case gets faster and cheaper.
The “Silo Sprawl” Trap
It starts innocently: maintenance wants
downtime analytics, EHS wants emissions
dashboards, finance needs throughput
reconciliations. Each team buys a tool that “just connects to the historian,” promising quick wins.
After a year or two, you’ve got:
- Five+ tools polling control systems (risking
poll storms and adding failure modes on
your most critical networks). - Conflicting numbers (which tag? which calc?
which time-base? which correction factor?). - Duplicated security reviews and access
paths into OT for each vendor. - Shadow data definitions (different
names/units for the same measurement). - Hard-to-upgrade spaghetti (every change to
a PLC tag, historian calc, or aggregation
breaks three dashboards and two models).
Silo sprawl boosts local speed but taxes
enterprise velocity. And it quietly blocks AI:
models starve without consistent, high-quality,
time-aligned, and contextualized data they can
trust.
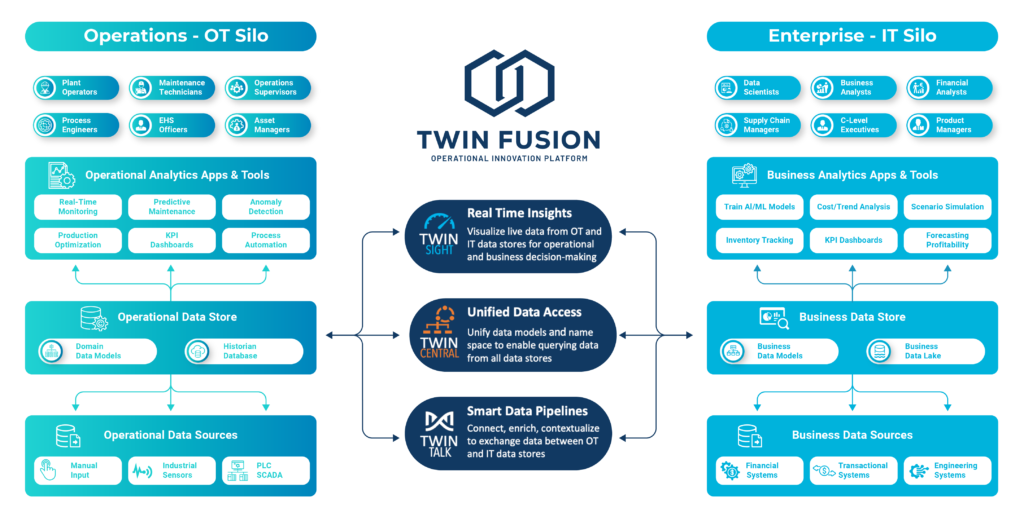
What a modern enterprise industrial platform is (and isn’t)
It’s not another dashboard. It’s a shared data
and control fabric that sits between OT and
every consumer (analytics, apps, AI) and
provides:
- Ingest once, serve many: Stream/ingest once
from historians or SCADA and serve
everywhere (APIs, events, tables, features). - Contextualization and a semantic model:
Assets, hierarchies, units, states, and
relationships (compressor → train → station
→ basin) so data is interpretable. - Time-series & event fusion: Align tags,
alarms, work orders, lab data, and meter runs
on a shared time-base. - Governance & lineage: Who can see what,
where the number came from, and how it
was calculated—auditable, repeatable. - Performance isolation: Queries for analytics
never jeopardize control traffic; historians
stay historians; control networks stay safe.
Why the platform approach wins (and keeps winning)
1) OT network safety. One hardened, rate-limited edge connection beats six ad-hoc vendor connectors. You eliminate poll storms and credential sprawl.
2) Single source of truth. KPIs and calculations are defined once in the platform’s semantic layer and reused across maintenance, EHS, finance, and AI pipelines—no more arguing about “which number is the number.”
3) Speed-to-value (compounding). The first use case lays the plumbing; the second, third, tenth use the same pipes. Each new app is 50–90% reuse (ingestion, cleanses, units, asset IDs, quality flags).
4) Lower TCO and vendor flexibility. Ingest once; serve many tools. Swap analytics workbenches or add a new app without touching OT again.
5) Data quality by design. Unit normalization, validity windows, sensor health, missing data rules, and state detection live centrally—your dashboards and models inherit quality instead of re-implementing it.
6) Future-proofing. When you build an open industrial data platform, migrations (new historians, cloud providers, or apps) stop being rewrites and become re-pointing exercises.
7) Governance & Observability. Role-based access control (RBAC), lineage, data contracts, audit logs, SLA monitoring, drift & data-health alerts.

In short, platform = AI-ready. Silos = “we’ll hand-export a CSV and see.”
A Quick Comparison at a Glance
| Dimension | Siloed “connect to Historian/SCADA” | Enterprise Industrial Platform |
|---|---|---|
| OT impact | Multiple connectors, poll storms | Single hardened ingress, rate limits |
| Data consistency | Conflicting KPIs, unit drift | Single semantic layer, one KPI definition |
| Security | Credential sprawl per vendor | Central authentication and authorization, audit, least privilege |
| Change management | Every tag change breaks multiple apps | Central mapping shields downstreams |
| Reuse | One-off transformations per tool | Shared transforms, features, context |
| Time-to-new use case | Weeks–months (new connectors) | Days (reuse pipelines & contracts) |
| AI readiness | Ad hoc CSVs, skew risk | Feature store, lineage, real-time inference |
| Auditability | Opaque calculations in siloed tools | End-to-end lineage and versioning |
| TCO | Compounds upward with each tool | Declines per use case as reuse grows |
- Days 1–15 — Pick one value path. Choose a use case with measurable dollars (e.g., compressor run-time to SAP for maintenance, emissions flare verification, or volumetric reconciliation). Inventory tags/events, define the KPI contract, and identify consumers (dashboard, API, ML).
- Days 16–45 — Build the spine. Stand up a minimal platform slice: edge ingestion → landing store → semantic model → serving table/stream → RBAC. No heroics; do the smallest thing that works safely.
- Days 46–75 — Deliver & prove. Light up the first dashboard/API and (if applicable) a small model (e.g., early-warning on surge, seal failure risk, or anomaly on duty cycle variance). Show lineage and governance alongside the chart—credibility matters.
- Days 76–90 — Reuse & scale. Plug a second consumer into the same data (finance, EHS, or reliability). Demonstrate reuse: same features/semantics, new outcome. Document the playbook.
If you’re debating the next project—another “just-connect-to-Historian” quick win or the first slice of a platform—pick the platform slice. It’ll pay for itself, then it’ll pay for everything after.
The EOT Solution
EOT Twin Fusion is an enterprise data fabric nocode platform that turns plant-level OT signals into governed, reusable, AI-ready data products. It ingests once from historians and SCADA (and others), fuses time-series with events, and applies a shared semantic model so KPIs and Analytics
are defined once and trusted everywhere. With a single hardened edge ingress and performance isolation, it protects control networks while serving cleansed data to BI, apps, and MLOps via open APIs, streams, and tables. Crucially, Twin Fusion doesn’t store your data—it orchestrates and serves it in your chosen data store or lake—backed by RBAC, lineage, and data contracts to avoid training/serving skew. The result: faster reuse, lower TCO, and no more “tap-the-SCADA”
one-offs.
Twin Fusion: OT Organized for AI and the Cloud