

Industrial Data Lake Solution
An Industrial Data Lake is a centralized storage repository that holds vast amounts of raw data from various sources across your organization. By using an Industrial Data Fabric (IDF) solution and its components – Twin Talk, Twin Sight, and Twin Central – you can design and create a powerful and flexible Industrial Data Lake that effectively manages your data and supports advanced analytics and machine learning applications.
Twin Talk serves as the foundation for building your Industrial Data Lake by providing secure, scalable data ingestion from SCADA systems and historians to the cloud. It eliminates the barriers associated with traditional data management systems, ensuring seamless data flow and integration.
Twin Sight offers an intuitive, user-friendly visualization tool and dashboard builder that allows you to access, analyze, and gain insights from the data stored in your Industrial Data Lake. With real-time data at your fingertips, you can make timely, informed decisions and optimize your operations.
Twin Central, the third IDF component, creates a comprehensive semantic data model for asset management. By linking, mapping, and managing all your metadata, Twin Central generates a single source of truth that unifies your entire organization’s data. This simplification of data management ensures efficient data access and streamlines analytics processes.
By leveraging the power of the IDF components, you can design an Industrial Data Lake that serves as a centralized data hub, breaking down data silos and fostering collaboration across departments. An Industrial Data Lake not only simplifies data management but also enables you to uncover new opportunities for improvement through advanced analytics, machine learning, and real-time data access. Embrace the potential of an Industrial Data Lake created with IDF components to transform your operations and maintain a competitive edge in the ever-evolving industrial landscape.
Architecture for an Industrial Data Lake with Twin Fusion
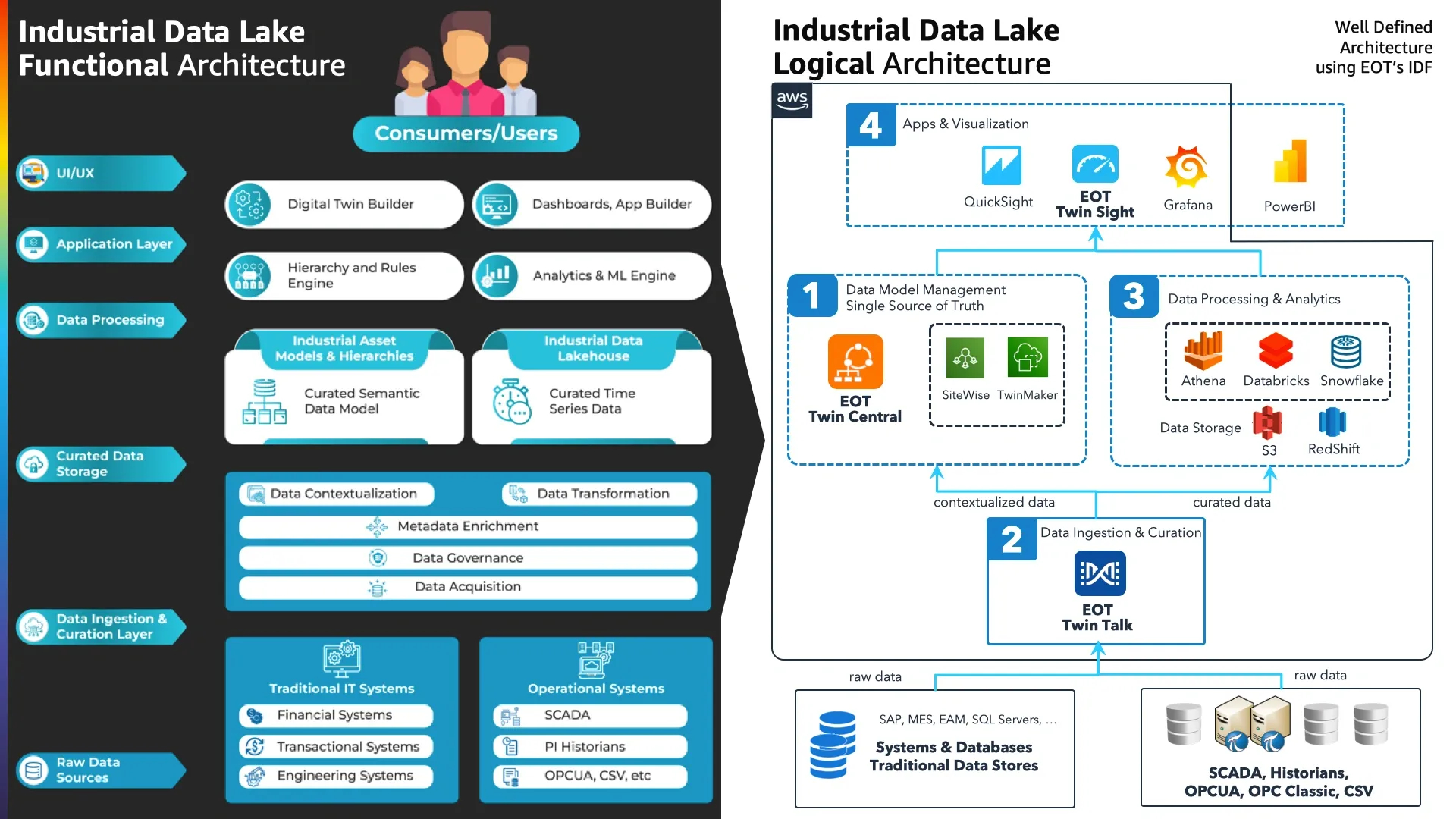
Designing and implementing an Industrial Data Lake architecture with EOT products is a game-changer, offering simplicity, stability, and speed. With no coding necessary and no need for “Lift and Shift” components like AWS Lambda, AWS Glue, or AWS Kinesis, EOT delivers a clean, elegant, and highly performant solution that outshines competitors. EOT’s user-friendly approach empowers organizations to harness their data’s full potential, accelerating data-driven decision-making while saving time and resources. Here are the for functional steps to get your first use case solution working:
- Begin by identifying the use cases that offer real business value, and use Twin Central to create Assets and Data Models. These will serve as the Single Source of Truth, enabling you to navigate through industrial assets within the Industrial Data Lake, dashboards, and visualization apps.
- With your valuable use cases in mind, utilize Twin Talk to configure Data Ingestion, Curation, and Contextualization. This process will transport and transform raw data from Data Sources into the data storage, making it ready for analysis.
- As you continue to focus on the specified use cases, train and deploy Analytics and Machine Learning (ML) models to provide valuable insights for the Industrial Data Lake, dashboards, and visualization apps.
- Finally, ensure that the Industrial Data Lake, dashboards, and visualization apps display operational, financial, and technical data, along with insights from analytics and ML systems, based on your identified use cases that offer real business value.
By following these four steps, you can effectively harness the power of an Industrial Data Lake to drive meaningful insights and informed decision-making for your organization.
How to Get Started
- Attempting to create an architecture that addresses all possible use cases for a company. This is often driven by business consulting firms that spend an excessive amount of time compiling use case lists involving the entire organization.
- Having no use case at all and adopting the mindset of gathering all data first, then discussing potential applications with users.
Both approaches almost certainly lead to costly projects that provide no value or support within the company and may even negatively impact the careers of project leaders. So, how should you get started? Select a use case that has two key attributes: 1) it’s quick to implement, providing a fast time-to-value, and 2) it delivers genuine business value for the company.
Industrial Data Lake Features and Benefits

An industrial data lake is a centralized repository that stores large volumes of structured and unstructured data from various sources within an industrial environment. This data can be used by industrial companies for advanced analytics, machine learning, and visualization applications, allowing them to gain valuable insights, optimize processes, and make data-driven decisions.
Analytics and Machine Learning Use Cases
- Predictive maintenance: By leveraging machine learning algorithms on the data stored within the industrial data lake, companies can predict equipment failures, enabling proactive maintenance scheduling and reducing downtime.
- Process optimization: Analytics tools can process the vast amounts of data within a data lake to identify inefficiencies, bottlenecks, and quality issues. This information can be used to optimize production processes, increase throughput, and minimize waste.
- Anomaly detection: Machine learning models can be trained to identify anomalies in operational data, alerting operators to potential issues before they escalate, thus improving safety and reducing the risk of equipment failure.
Visualization Use Cases
- Real-time monitoring: Visualization applications can be used to create dashboards that display real-time data from the industrial data lake, providing operators with a comprehensive overview of asset performance and enabling faster, more informed decision-making.
- Remote collaboration: Industrial data lakes facilitate collaboration between onsite and remote teams by providing access to real-time data and visualizations, allowing experts to review and analyze data from anywhere, leading to better decision-making and improved asset performance.
- Customized reporting: Visualization applications can be employed to generate custom reports, tailored to individual use cases, that analyze and present data from the industrial data lake in a clear, accessible manner. These reports can be used to communicate insights to stakeholders and drive data-driven decision-making.
Twin Fusion Components for Industrial Data Lake

EOT’s Twin Talk™ serves as a Data Integration Platform for industrial IoT, bridging the gap between operational systems (OT) and cloud (IT) solutions to unlock the untapped value of operational data. This innovative solution eliminates the complexity and costs associated with traditional infrastructure, enabling executives, operators, data scientists, and business analysts to harness AI, machine learning, and analytics for real-time insights and operational intelligence. Twin Talk streamlines the secure transmission of sensor data from assets while maintaining plant safety, allowing companies to focus on enhancing productivity through digitization and driving tangible business value.
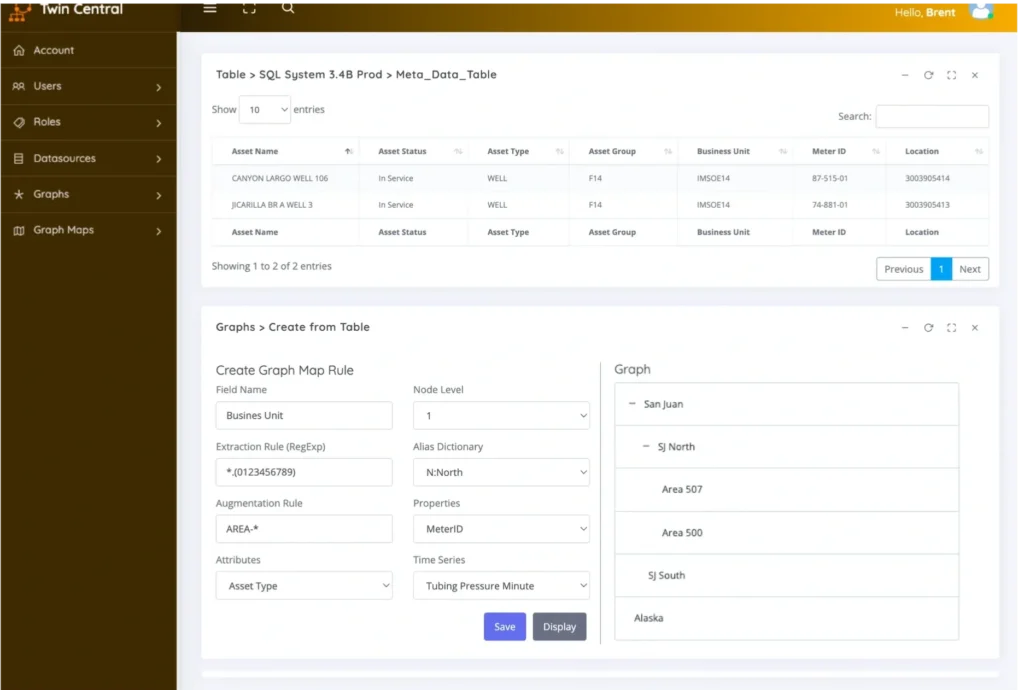
EOT’s Twin Central™ facilitates the creation of an asset-centric, single source of truth semantic data model. With Twin Central, business technologists can map, link, store, and synchronize relationships between assets and their operational, engineering, and financial metadata using a unified relationship graph. This straightforward approach enables the creation and management of an asset-centric, single source of truth and semantic data model across the enterprise. Twin Central allows for the development of digital twin data models that map, connect, link, store, and synchronize relationships between assets and their operational, engineering, and financial metadata using a unified digital twin relationship graph.

EOT’s Twin Sight™ offers a modern, rapid prototyping approach to operational dashboard authoring, accelerating the adoption of AI-based anomaly detection, production optimization, and operation monitoring across all production sites. With Twin Sight™, industrial users can leverage the power of low-code AI-driven software to modernize the visualization of asset information and data, driving the rapid creation of use-case-specific visual dashboards, templates, and reports. Twin Sight’s flexibility and ease of use enable any individual within the company to access enterprise-wide operational data through a self-service model and develop dashboards and reports tailored to their specific use case and business needs.