
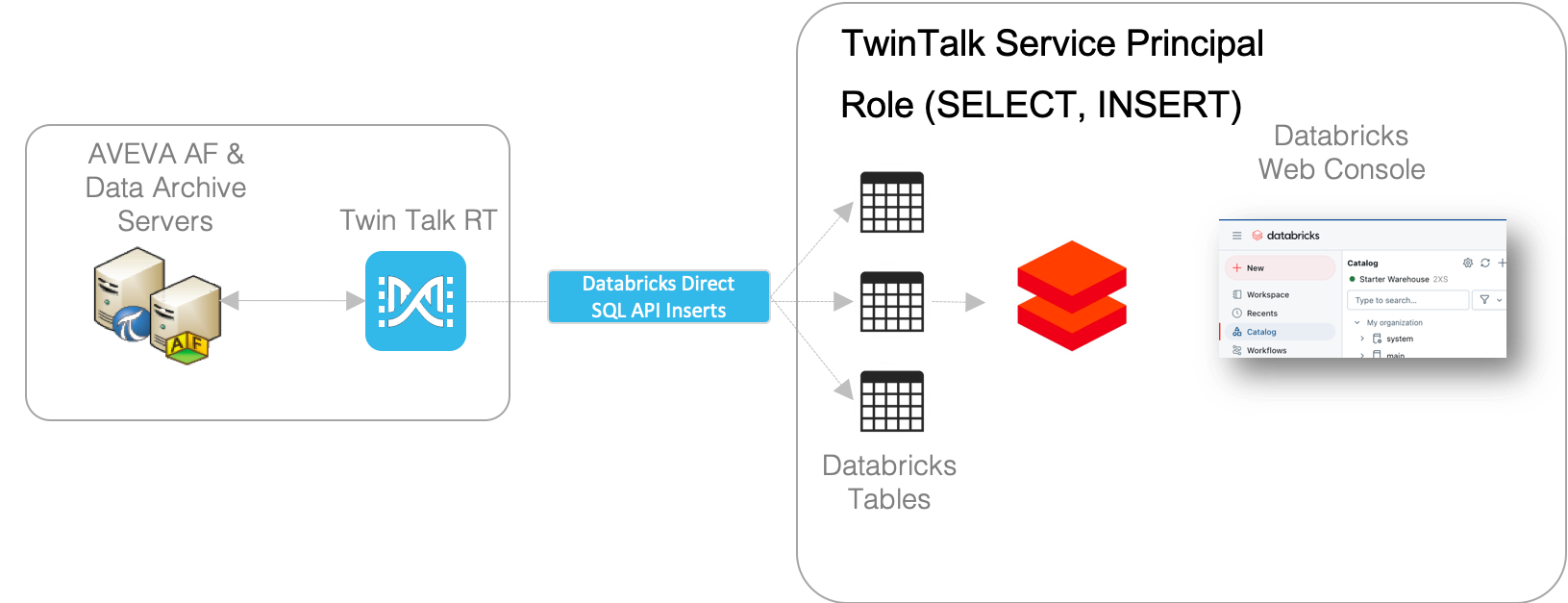
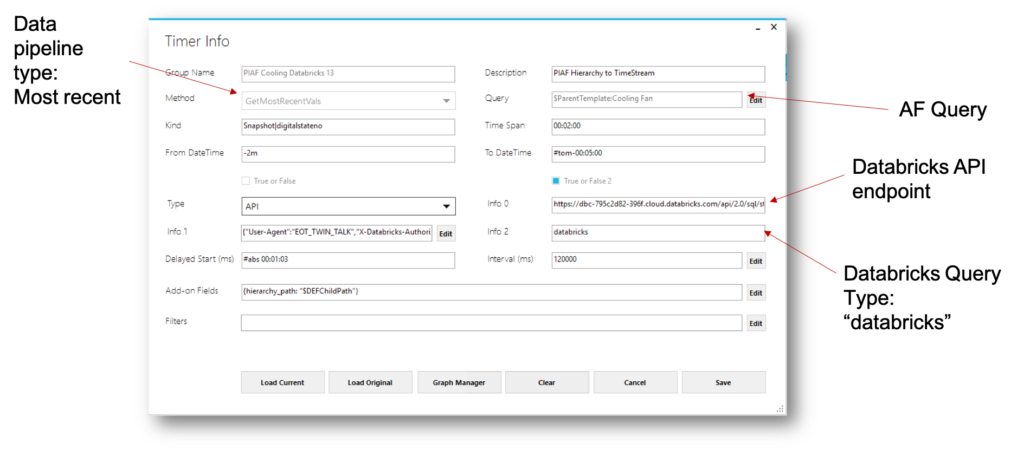

Enterprise Industrial Platform
Why an enterprise industrial platform beats siloed tools — and unlocks aifor operations Point solutions that pull directly from historians or SCADA solve one problem

Reimagining industrial intelligence: How cloud historians can disrupt the automation landscape
EOT.AI’s “Twin Fusion” redefines industrial data handling – merging AI, cloud-native scalability, and real-time intelligence.
Learn how this disruptive approach changes the automation game.
Using ChatGPT to Build an IIoT Anomaly Detection Model and Export to ONNX for TwinSight
In this article, we’ll walk through how to use ChatGPT to create a Python program that: Loads and processes IIoT time series data, Trains an anomaly detection model to detect overheating, Converts the trained model to ONNX format,
Prepares it for deployment using TwinSight Machine Learning Workbench

Beyond data: What ‘Integrated Information Theory’ can teach us about AI and Digital Twins
Discover how Integrated Information Theory [IIT] reshapes the future of AI and Digital Twins.
Learn why connecting and integrating data is the key to building intelligent, adaptive operations.

From data silos to real-time twins – Why 2025 is the year of operational AI
AI isn’t just a trend – it’s transforming how industrial leaders harness their data.
Here’s how EOT.AI helps teams scale innovation from the shop floor to the cloud.

Reflections from AVEVA World 2025 – EOT.AI at the frontier of industrial AI
Explore EOT.AI’s key takeaways from AVEVA World 2025 in San Francisco.
Learn how industrial AI, digital twins, edge computing, and generative AI are shaping the future of data-driven operations.
Enterprise Industrial Platform
Why an enterprise industrial platform beats siloed tools — and unlocks aifor operations Point solutions that pull directly from historians or SCADA solve one problem
Reimagining industrial intelligence: How cloud historians can disrupt the automation landscape
EOT.AI’s “Twin Fusion” redefines industrial data handling – merging AI, cloud-native scalability, and real-time intelligence.
Learn how this disruptive approach changes the automation game.
Using ChatGPT to Build an IIoT Anomaly Detection Model and Export to ONNX for TwinSight
In this article, we’ll walk through how to use ChatGPT to create a Python program that: Loads and processes IIoT time series data, Trains an anomaly detection model to detect overheating, Converts the trained model to ONNX format,
Prepares it for deployment using TwinSight Machine Learning Workbench
Beyond data: What ‘Integrated Information Theory’ can teach us about AI and Digital Twins
Discover how Integrated Information Theory [IIT] reshapes the future of AI and Digital Twins.
Learn why connecting and integrating data is the key to building intelligent, adaptive operations.
From data silos to real-time twins – Why 2025 is the year of operational AI
AI isn’t just a trend – it’s transforming how industrial leaders harness their data.
Here’s how EOT.AI helps teams scale innovation from the shop floor to the cloud.
Reflections from AVEVA World 2025 – EOT.AI at the frontier of industrial AI
Explore EOT.AI’s key takeaways from AVEVA World 2025 in San Francisco.
Learn how industrial AI, digital twins, edge computing, and generative AI are shaping the future of data-driven operations.